The following will act as lecture notes to help you review the material from lecture for the
assignment. You can click on the links below to get directed to the appropriate section or
subsection.
In computer graphics, we approximate the surfaces of solid objects by discretizing them as sheets
of the simplest 2D surface: the triangle. We saw this to an extent in Assignment 1 where our
wireframes consisted of many small triangle frames. We will now fill in these triangle frames to
render solid surfaces.
To render a solid triangle, we find it convenient to assign information such as color to the triangle
vertices and then interpolate this information across the triangle. For instance, to indicate that a
right triangle face has a color gradient of say red to blue from the hypotenuse to the opposite point
, we would assign
the color vector
(i.e. 100% red, 0% green, 0% blue) to the endpoints of the hypotenuse and the color vector
(i.e. 0% red, 0%
green, 100% blue) to .
Interpolation then mixes the colors across the triangle to form the gradient.
There are a variety of interpolation schemes out there, but the simplest method is to use
barycentric coordinates. We will develop these coordinates from scratch.
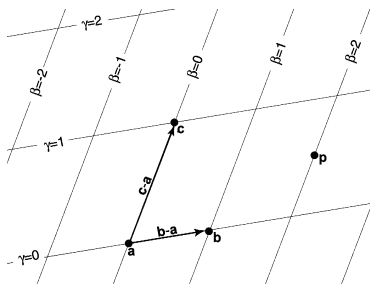
Consider a triangle in 2D space with vertices
. From these vertices,
we can form the vectors
and .
Recall from basic linear algebra that we can span a 2D coordinate space given a point
in the space and two linearly independent vectors. We know that the two vectors
and
have to be linearly independent;
otherwise, the vertices ,
, and
would not form a triangle.
Hence, with point
and basis vectors and
, we can express the
coordinates of any point
in the space as the following linear combination:
for real coefficients
and .
We can then reorder the terms in the above equation to get:
and define, for convenience,
to rewrite the above equation as:
with the constraint that:
The barycentric coordinate system is the 2D space spanned by
and
with origin
. The
vectors
and
are generally non-orthogonal. Figure 1 shows an example of a barycentric coordinate
system:
Figure 1: A triangle with vertices
can be used to set up a barycentric coordinate system with origin
and basis vectors
and
.
Points are represented as ordered pairs of
- e.g.
.
This diagram is taken from [1].
We can compute the barycentric coordinates for an arbitrary point
by
rewriting:
as the following linear system:
Solving for
and
gives us:
Once we have
and , we can
compute
using the definition:
Note that the equations for ,
, and
all
have similar numerators and denominators. We can use this fact to our advantage to simplify our
implementation of barycentric coordinates. Consider the following function:
We can express the equations for ,
, and
in terms
of in
the following manner:
The above representations allow us to compute barycentric coordinates by simply implementingthe function and calling it repeatedly with the appropriate parameters.
The power and convenience of barycentric coordinates will become evident once we analyze them
for a point inside the original triangle that we used to establish the coordinates.
First, consider what happens to ,
and
for a point inside the
triangle formed by vertices ,
, and
back in Figure 1. It
is obvious that and
must be between 0 and 1. The
line segment can be expressed
as part of the line or more
usefully as in barycentric
coordinates. If is part of
, then the area to the left of
, including the entire area
of the triangle, must be .
And if is true for a point
inside the triangle, then
must be between 0 and 1. Hence, a point is only inside a triangle if and only if itsbarycentric coordinates for that triangle obey the following inequalities:
It is straightforward to also see that for a point directly on an edge of the triangle, the twobarycentric coordinates associated with the edge endpoints must be between 0 and 1while the remaining coordinate must be 0. And for a vertex of the triangle, thebarycentric coordinate associated with that point must be 1 while the other two mustbe 0.
The above results can be used to devise an algorithm that determines which pixels
in a pixel grid to fill when rasterizing a triangle. Given the triangle vertices in screencoordinates, we would first find the bounding box for the three vertices - i.e. we find the
smallest rectangle of pixels in the grid that encompasses all three vertices. From there, we
consider each pixel within the bounding box and compute its barycentric coordinates using
the vertices of the triangle. We use the barycentric coordinates to determine whether
the pixel is inside or on an edge of the triangle and fill in the pixel if either case is
true.
We next look at what barycentric coordinates are mainly used for in computer graphics:
interpolating arbitrary values across a triangle. Consider how we linearly interpolate a value
located at
in some 1D space
between two values
located at
and
located at :
We assign a weight to one of the known values
in our weighted sum based on the distance between the unknown value
and the other known
value . As a result,
the closer is to
, the larger the weight
assigned to becomes.
And the further away
is to ,
the smaller the weight becomes. Figure 2 shows a visual of this:
Figure 2: To linearly interpolate an unknown value
(in purple) between two known values
(in blue) and
(in yellow), we compute a weighted sum where the weight for
is proportional to the blue distance and the weight for
is proportional to the yellow distance. In this case,
is closer to
than
,
hence
gets assigned more weight as shown by the longer blue distance.
Interpolating a value
among three values
uses the same idea of assigning weights, except it bases the weights on areas instead of
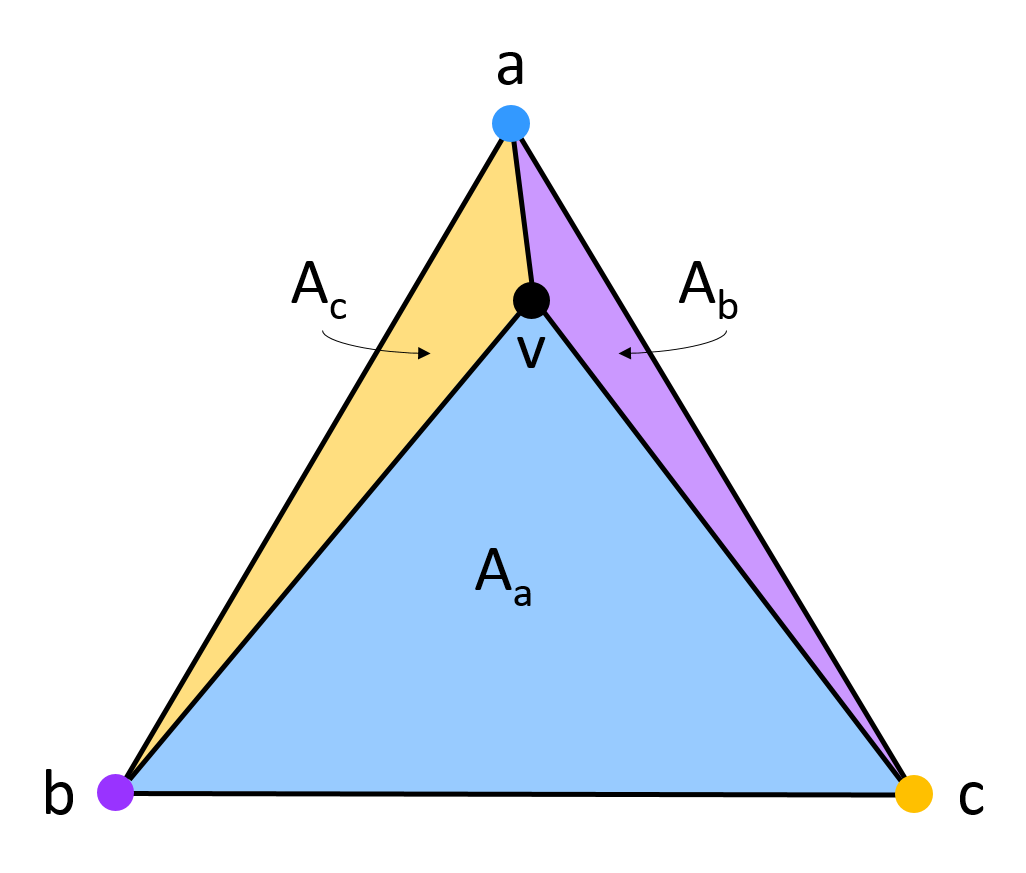
one-dimensional distances. Consider Figure 3:
Figure 3: To interpolate a value
(in black) among three values
(in blue),
(in purple), and
(in yellow), we compute a weighted sum where the weight for
is proportional to the blue area,
,
the weight for
is proportional to the purple area,
,
and the weight for
is proportional to the yellow area,
.
In this case,
is closest to
,
hence
is the largest weight. Between
and
,
is closer to
,
hence
.
Let be the area of triangle
in Figure 3. Then our
weighted sum for interpolating
is:
It turns out that we can compute the areas
and using the barycentric
coordinates for .
Let us assign each value an appropriate ordered pair
in
Cartesian coordinates. Recall from basic geometry that the area of a triangle with vertices
is
given by the following determinant:
Let us compute the area of triangle
in Figure 3:
The weight assigned to vertex
in the interpolation is then:
The expression on the right-hand side should look familiar. Recall the formula we got for
and
fully expand the products:
Factor out a negative sign from both the numerator and denominator
of the right-hand side expression in the above equation and replace
with
to
get:
It can be shown through similar means that:
Hence, we can simply interpolate our unknown value
as:
just like how we would interpolate the coordinates of a point
within
a triangle. This should not be too surprising of a fact, since when we started to consider the values
under a Cartesian coordinate system, we reduced the problem of interpolating
to the problem of interpolating the coordinates of a point
in a
triangle.
The important lesson here is that barycentric coordinates allow us to interpolate any unknownvalue among three known values. We could, for instance, use them to interpolate the color of apoint intriangle :
where
refer to the red, green, and blue color values. Let us now update the algorithm that we devised
earlier to include color interpolation.
Do note that this algorithm does not properly handle pixels whose centers are exactly on an edge
shared between two adjacent triangles. There is no obvious way to associate the pixel with one of
the triangles over the other. The above algorithm does not bother to make any sophisticated
decisions and instead draws any shared edges twice, with the edge of the second triangle
overwriting the edge drawn for the first triangle. In practice, this is not that big of an
issue, since adjacent triangles in our solid objects tend to not differ too drastically in
color.
However, there are various heuristics out there that try to assign pixels on shared edges
appropriately to only one of the two triangles. Unfortunately, these heuristics are outside the scope
of the class. For those who are curious, pages 168-169 of [1] present an overview of one possible
heuristic.
While barycentric coordinates are mostly used with triangles, they have also been generalized for
n-sided polygons. This generalization is outside the scope of this class, but for those who are
interested, we have provided a link [2].
To achieve a 3D effect when we render surfaces, we use lighting and shading. In this section, we
will talk about lighting; we cover shading in the next section.
The most commonly used lighting model is the Phong reflection model, also known simply as
the lighting model. This model is often ambiguously referred to as Phong shading even though
there is also the Phong shading algorithm, which we will cover in a later section. To avoid
ambiguity, many people simply refer to the model as the lighting model. For this class, we will
also refer to it as the lighting model, and like with barycentric coordinates, we will develop the
model here from scratch.
All lighting and shading calculations involve unit surface normals. So before we get into the
lighting model, we need to first discuss unit surface normals in computer graphics.
Recall from multivariable calculus that the unit surface normal at a point
on a
surface is defined to be the unit vector pointing in the direction perpendicular to the tangent plane
at .
This definition causes some issues for when we represent parts of curved surfaces as flat
triangles in computer graphics. For a curved surface like a spherical shell, each point on the
surface has its own different unit surface normal, since each point has its own different
tangent plane. However, for a flat surface like a triangle, each point on the surface shares
the same unit surface normal, since all the points share the same tangent plane. This
difference poses the question of how we should represent unit surface normals on our
discretized surfaces. Should we still treat our triangulated surfaces as though it were still
the original curved surface, or do we treat each discrete triangle as an individual flat
surface?
To render realistic lighting, we need to still treat triangulated surfaces as though it were still the
original curved surface. This means that each of the three vertices of a triangle in ourdiscretization of say a spherical surface has a different unit surface normal, eventhough the vertices are all part of the same flat triangle. This may seem unintuitive, but in
this case, we need to treat our discretizations as though they were non-discretizations in order to
portray realism.
We will cover how to compute the unit surface normals for points on a discretizedsurface in a later assignment. For now, we will assume that we are provided the unit surface
normals whenever we need them for a computation.
As we might expect, the unit surface normals for points inside a triangle on ourdiscretized, curved surfaces can be computed by interpolating the unit surfacenormals of the three triangle vertices using barycentric coordinates.
Transforming normals is a bit different from transforming points in world space. First,
it is clear to see that translations are irrelevant for normals. We can translate a normal all we
want, but the normal will still be the same vector. Rotations and scalings still have an
effect, but we cannot simply apply them to normals the same way that we would to
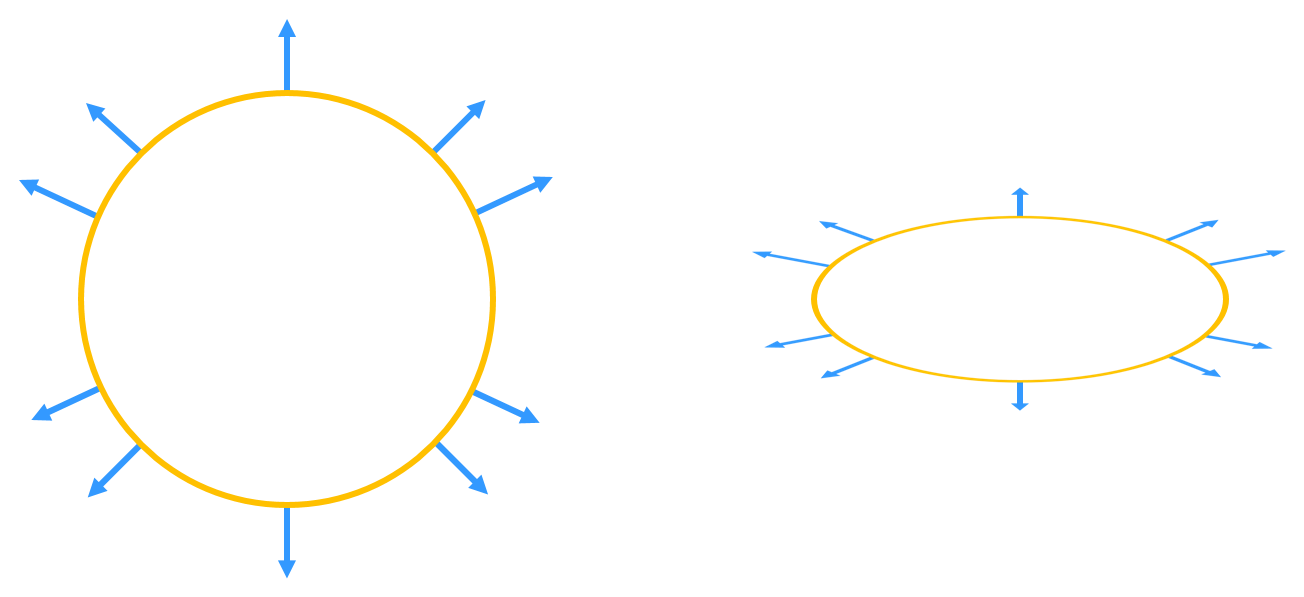
point coordinates. Consider, for instance, a non-uniform transform that scales each axis
by a different factor in such a way as to “stretch” a circle into an ellipse as in Figure
4:
Figure 4: A non-uniform transform is applied to the circle on the left, scaling each axis by
a different factor to “stretch” the circle into an ellipse. The same transform is applied to
the circle’s normals. As we can see, not all the resulting vectors on the ellipse are
perpendicular to their incident tangent planes; they are not all correct normals.
The vectors displayed on the ellipse are what we would expect if we transformed the original
normals of the circle by the matrix we used to transform the circle itself. However, we can clearly
see that not all the vectors on the ellipse are perpendicular to their incident tangent planes, and
hence, they are not proper normals.
We have to derive a different transformation scheme that properly transforms the original normal
for a point
on a surface to
the new normal
for on
the transformed surface. Note that because translations are irrelevant, we have no need for the
fourth row or column in any normal transformation matrix. Hence, we only need to work with 3x3
matrices when dealing with normals.
Let
be the normal transformation matrix that we are trying to find - i.e.
. Let
be the tangent plane
incident to and hence
perpendicular to normal .
Let be
the overall 3x3 transformation matrix (neglecting translations as they are irrelevant) such that
is the transformed
tangent plane. Since
and
are perpendicular, we can write:
Then, using properties of transposes and the associative property of matrix multiplication:
We can clearly see that the above equation is satisfied if
, the identity
matrix, since .
Solving for
from
gives us:
Hence, to transform normals appropriately, we use the inverse transpose of thetransformation matrix we use for points, neglecting the translation components.
For instance, suppose our transformations for our points in world space consist of a translation
, followed by a
rotation , followed
by a scaling .
The matrix we would use to transform our normals then would be:
As a final note, any calculations involving surface normals should always bedone in world space. This includes the computations in the lighting model and the
shading algorithms in the following section. The math behind these calculations were all
made in standard Cartesian coordinates and not the warped, camera and perspective
coordinates.
The first component of the lighting model is diffuse reflection. Diffuse reflection is the reflection
of light off a surface at many angles; the incident ray hits the surface and out forms many
scattered, reflected rays at various angles. This causes the effect where the color and brightness of a
point on a surface appears relatively constant despite changes in our viewpoint. Objects that
primarily reflect diffuse light include paper, unfinished wood, and unpolished stones. We model
diffuse reflection by considering the characteristics of an ideal diffuse reflecting surface, which
reflects incoming light equally at all angles. An ideal diffuse reflecting surface is also known as a
Lambertian surface, hence, the model we use for diffuse reflection is known as Lambertianreflectance.
A Lambertian surface obeys Lambert’s cosine law, which states that the luminous intensity of a point
on the surface is proportional
to the cosine of the angle
between the incident light ray and surface normal. For our purposes, luminous
intensity is equivalent to magnitudes of RGB color values. Hence, letting
be our
color vector of RGB values, we have:
Letting be the unit vector in
the direction of the light from
and be the unit
surface normal at ,
we can express the cosine as the following dot product:
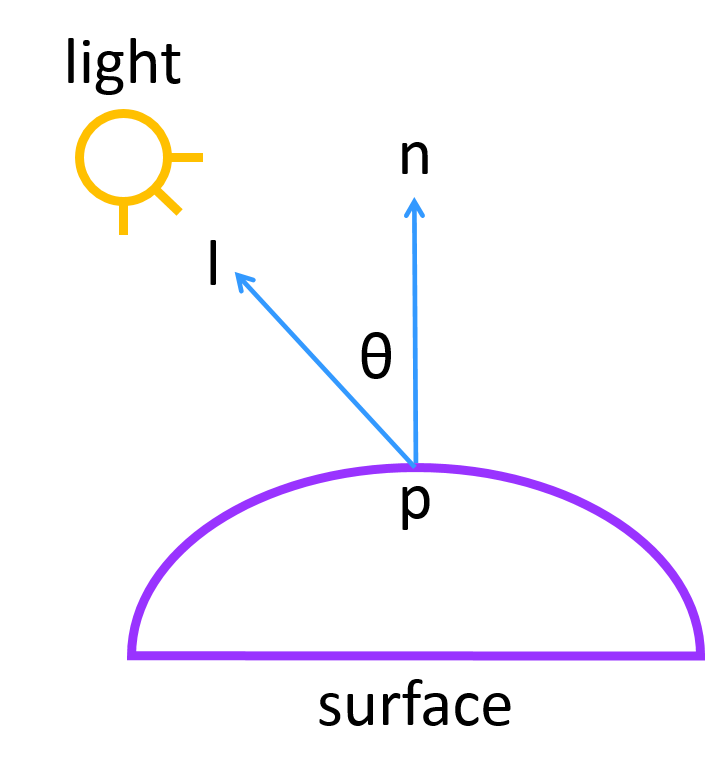
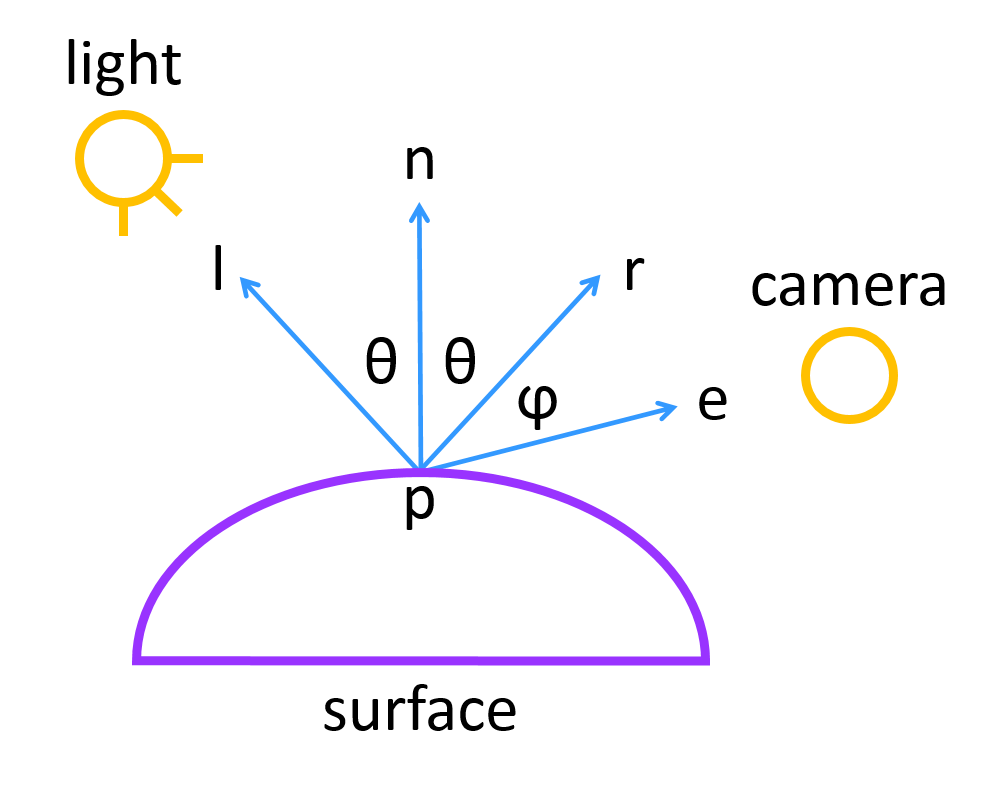
Figure 5 shows a diagram of the vectors involved in the calculation:
Figure 5: A visual showing
,
the unit vector in the direction of the light from point
,
and
,
the unit surface normal at
.
We can express
as
.
The color of our point should also depend on the surface’s diffuse reflectance, an inherent property
of the material that determines the fraction of incoming diffuse light reflected by the surface. The
fraction is different for each wavelength of light; or in our case, it is different for each color component.
Let be
our vector of fractional values for diffuse reflectance. Then:
Finally, the magnitude of our color values should depend on the intensity of the light as well. Let
be our
vector of fractional values that determine the fraction of outgoing light (i.e. each color component
of outgoing light) from the light source. Then:
The above equation is our model for diffuse reflectance. However, we need to be
cautious of the dot product, since it can be negative for cases where the surface normal
points
away from the light source. In these cases, the surface should recieve no light illumination (i.e.
)
because it is not facing the light. We can account for these cases with a max function:
We cannot solely use diffuse reflection as our lighting model because points whose normals point
away from the light(s) will be colored entirely black. However, in reality, there will always be some
light reflected off the surroundings to illuminate even the surfaces that face away from
the light(s). We refer to this lighting as ambient light and its reflection as ambientreflection.
Let us consider how ambient light interacts with a single point on a sufrace. Since ambient light
has been reflected and scattered so much by the environment, it appears to come from all
directions as it hits the point. Hence, we model ambient light as though it is incoming from all
directions. Additionally, very little ambient light often reaches our eyes after bouncing off the
environment. As a result, points illuminated by just ambient light appear to have constant color
even when we change our viewpoints, just like points illuminated by only diffuse light on
a Lambertian surface. Thus, we also take ambient light to be reflected equally in all
directions.
Since ambient light has absolutely no directional or single light source dependence, we can
represent it in our lighting model by solely looking at how much ambient light a surface reflects.
That is, given a particular surface, we just need to look at its ambient reflectance,
an inherent propety of the material that determines the fraction of incoming ambient
light reflected by the surface. The concept is very similar to diffuse reflectance. Let
be our vector of fractional values for a surface’s ambient reflectance. We factor
into
the diffuse reflection model from the previous subsection:
Note that the sum may result in a color vector with components greater than 1. Inthese cases, we would need to clamp any components over 1 down to 1, as we cannothave over 100% of a color component.
The final component of the lighting model accounts for specular highlights, the bright spots of
light that appear on illuminated shiny objects. If we were to look carefully at specular highlights in
real life, we would see that they are simply direct reflections of light. Hence, to model specularreflection on a given surface for a given light source, we would need to create a bright spot on the
surface such that the center of the spot is the point where the direction of the camera vector
lines up with the direction of light reflection, which we will represent as vector
. This
would model the direct reflection of light to our eyes produced by real specular highlights. We use
here instead of
for the camera vector
due to already referring
to color vectors, and
is often used when people refer to the camera space by its equivalent eye space name.
To model the size of the bright spot, we would like some sort of function
that causes the color at a point on our surface to be bright when
and dim
as moves
away from .
The natural thing to do would be to have the function depend on the cosine of the angle between
and
- i.e.
the color is brightest when the cosine is 1 and dimmest when the cosine is 0. Letting
and
be unit
vectors, we can express the cosine as a dot product. Also, similar to diffuse reflection, specular
reflection should factor in the color of the incoming light from the light source and the specularreflectance
of the surface material. Putting all these factors into one formula gives us:
Figure 6 shows a diagram of the vectors involved in the calculation:
Figure 6 A visual showing
,
the unit vector in the direction of the light from point
;
,
the unit surface normal at
;
,
the unit vector in the direction of the camera from
;
and
,
the unit vector representing the reflection of the light at
.
Our specular highlight should be brightest when
is 0 or
is 1. We can express
as
.
Like with the dot product in our diffuse reflection model, we need to account for negative values
using a max function. Also, it turns out that, in practice, the above formulation actually results in
a specular highlight that is much wider than what we would see in real life. The maximum color
and brightness of the center point turn out correct, but the radius of the highlight is too big. To
address this issue, we can dampen the brightness of the color much faster as the angle between
and
increases by raising the dot product to a positive, real number exponent:
We call the
Phong exponent
is also referred to as the shininess value and is treated as a propety of the surface
material. For instance, a very shiny surface like polished metal would have a
value close to 1. Figure
7 shows the effect that
has on the size of the specular highlight:
Figure 7: The specular highlight increases in size as the Phong exponent
decreases. This diagram is taken from [1].
Computing the dot product in our model is not trivial though since we have to compute
. A
cleaner way to accomplish what we want is to actually use the vector halfway between
and
. Call this
vector . Then
when lines
up with ,
should line up with the surface
normal vector . Hence, the
cosine of the angle between
and can be used instead of the
cosine of the angle between
and .
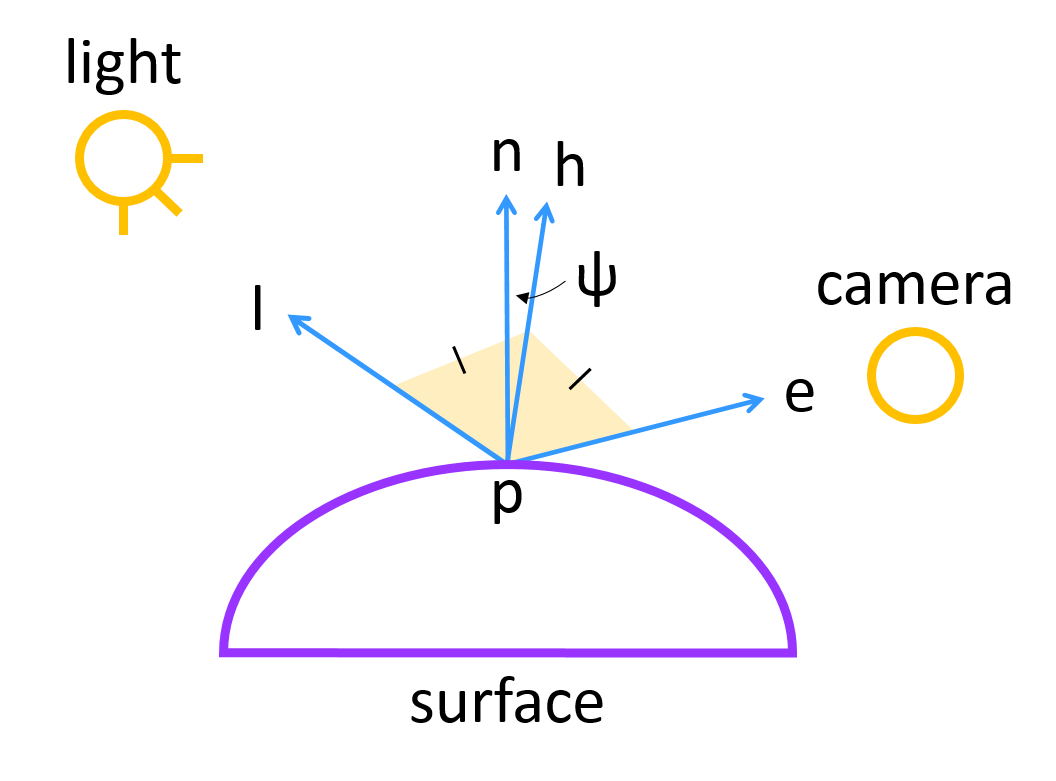
Figure 8 shows a visual of the vectors:
Figure 8: A visual showing
,
the unit vector halfway between
and
.
When
and
from Figure 6 line up,
and
will also line up. Hence the angle
between
and
can also be used for computing specular reflection, just like
could be used in Figure 6. We can express
as
.
Note that we use cwise_min and
in line 23 to denote the component-wise min function and component-wise product of two vectors
respectively.
Recall that all calculations involving normals should be done in world space.Hence, these lighting and color calculations should be done before any cameraand perspective transformations. Also note how the above algorithm uses triples of
rather
than homogeneous coordinates. This does not matter too much since the homogeneous
components of our coordinates in world space should all be 1, so we can just ignore the
values.
However, it is something to keep in mind when implementing the algorithm.
The lighting model does not take into account the distance between a light source and the point
that is being processed. However, in real life, moving a light source further away from a point
should dim the amount of light that illuminates the point. We call this loss of light intensity over
distance attenuation.
We represent attenuation with a percentage indicating the amount of
remaining light. For instance, an attenuation of 0.4 or 40% for a light
at some point
means that only 40% of
the light intensity from
affects
and 60% of the light intensity has been lost.
In real life, attenuation follows an inverse square law where the light intensity is
proportional to one over the square of the distance. However, when we model
attenuation, we use a slightly modified inverse square relationship where we include
an additive factor of 1 to avoid situations where we might get a divide-by-zero. Let
be the vector of color values representing the light for light source
and
be the distance
between
and point .
Our attenuation model is then as follows:
This model allows the light intensity to be maximum when
.
Often, we include a multiplicative factor
in the model to control the amount of attenuation:
The above modification allows us to make different lights attenuate differently by assigning them
different
values. In addition, it allows us to account for different degrees of attenuation depending on the
medium that we want the light in. For instance, we would want the attenuation of light traveling
through water to be different from the attenuation of light traveling through air in our
programs.
To incorporate attenuation into the lighting model, we just need to computethe attenuation of the light during each iteration of our loop and reduceby the computed valuebefore computing and .
With barycentric color interpolation and the lighting model, we can finally devise an algorithm for
appropriately coloring or shading an entire surface of a solid surface illuminated by light sources.
There are two commonly used shading algorithms known as Gouraud shading and Phongshading. Gouraud shading and Phong shading are also associated with per vertex lighting and
per pixel lighting respectively. The meaning of these names will become clear as you read about
these algorithms. There is also another shading algorithm known as flat shading that is
sometimes used for its simplicity.
The Gouraud shading algorithm is named after Henri Gouraud, who first published the
technique in 1971. The idea behind Gouraud shading is that for each triangle in our solid surface
representation, we use the lighting model to calculate the illuminated color at each vertex and then
use barycentric interpolation to rasterize the triangle. Since the lighting is computed at each
vertex, Gouraud shading is often referred to as per vertex lighting. We can write the following
pseudocode for the algorithm:
Note that the above algorithm passes NDC into Raster_Colored_Triangle rather thanscreen coordinates. We could put the conversions to screen coordinates within the
Gourad_Shading function as well, but doing so will make it harder for us to later incorporate
depth buffering and backface culling, which we will cover in the next section. For now, we will
put the conversions to screen coordinates in Raster_Colored_Triangle in the following
manner:
Notice line 17, where we check whether our interpolated point in NDC is within the bounds of our
cube (recall how we “shrink” our viewing frustum into a cube when we convert from camera
coordinates to NDC). We place the check here so that a triangle that is partially outside our “NDC
cube” will still have its parts within the cube rendered.
Note that this is not the full Gouraud shading algorithm. The full version,which incorporates depth buffering and backface culling, is discussed furtherbelow.
Figure 9 demonstrates Gouraud shading on a sphere using two different colored lights.
Figure 9: A red sphere illuminated by two different colored lights and rendered using
Gouraud shading.
Flat shading is the most basic shading algorithm. The idea behind flat shading is that for each
triangle in our solid surface representation, we call the lighting model function once with
the average vertex position and average normal and then use the resulting color for
every pixel we rasterize on the triangle. We can write the following pseudocode for the
algorithm:
where Raster_Flat_Colored_Triangle would be the same as Raster_Colored_Triangle, except it would color
each pixel using
rather than interpolated color values. Note that this algorithm is not complete; we would want to
incorporate depth buffering and backface culling for full efficiency. These two topics are discussed
in the next section.
Compare the following sphere image in Figure 10 with the the sphere image in Figure 9. The one
in Figure 10 was rendered using flat shading while the one in Figure 9 was rendered using Gouraud
shading. We see that flat shading resulted in a more blocky and unrealistic looking coloring.
However, because flat shading is so simplistic, it performs much faster than Gouraud shading. As a
result, flat shading provides a faster alternative to Gouraud shading if detail is not a
priority.
Figure 10: A red sphere illuminated by two different colored lights and rendered using flat
shading.
Phong shading is named after Bui Tuong Phong, who published the technique in 1973. It is the
most complex of the three shading algorithms and produces what many consider the “best”
shading effect.
Instead of interpolating the colors across the vertices like in Gouraud shading, Phong shading
interpolates the world coordinates and normals of the vertices across the triangle. Then, during the
rasterization process, for each pixel we rasterize, we call the lighting model with the world
coordinates and normal corresponding to the pixel and rasterize the pixel with the resulting color.
This technique produces a smoother shading effect than Gouraud shading, but at the cost of more
computation; hence, Phong shading does not completely overshadow Gouraud shading. Since
Phong shading computes the lighting per pixel, it is often referred to as per pixellighting.
We can write the following pseudocode for the algorithm:
Algorithm 7:
1:functionPhong_Shading( materiallightsgrid) 2: NDC_To_Screen 3: NDC_To_Screen 4: NDC_To_Screen 5: 6: Min 7: Max 8: Min 9: Max 10: 11:fordo 12:fordo 13:Compute_Alpha( 14:Compute_Beta( 15:Compute_Gamma( 16:if && && then 17:ifthen 18: 19: 20:color Lightingmateriallights 21: Fill( grid, color) 22:endif 23:endif 24:endfor 25:endfor 26:endfunction
Note that ,, andinline 19 are in world coordinates.
Compare the following sphere image in Figure 11 with the the sphere image in Figure 9. The one
in Figure 11 was rendered using Phong shading while the one in Figure 9 was rendered using
Gouraud shading. If you concentrate on the specular highlights, then you can see that the
highlights in the image rendered with Gouraud shading are a bit pixelated while the highlights in
the image below are much smoother looking.
Figure 11: A red sphere illuminated by two different colored lights and rendered using
Phong shading.
Note that this algorithm is not complete; we would want to incorporate depthbuffering and backface culling for full efficiency. These two topics are discussed in thenext section.
Because the shading algorithms can be computationally intensive, we do not want to waste
computation time trying to render anything that we do not need. For instance, if a triangle
were behind
another triangle
that is closer to the camera, then we should not waste computation time rendering
when
will be
blocking it from our view. We handle these kinds of cases with depth buffering and backfaceculling.
Depth buffering allows us to determine whether a point that we are trying to rasterize is behind
another point and thus should not be rasterized. We do depth buffering in the following
manner:
Create a “buffer grid” with the same dimensions as our raster grid.
Initialize every element of the grid to a very high value (e.g. the maximum double
value).
For each point
that we consider rasterizing at
in our raster grid, check whether the z-position
of the point in NDC is less than the value stored at
in the buffer. If it is, then we set that value at
in our buffer to
and render the point .
Else, we do not render
or change the buffer.
Basically, our “buffer grid” keeps track of the relative distance in NDC between the camera and
the closest point to the camera at each square of our raster grid. This allows us to easily check
whether a point we are trying to render is behind another point.
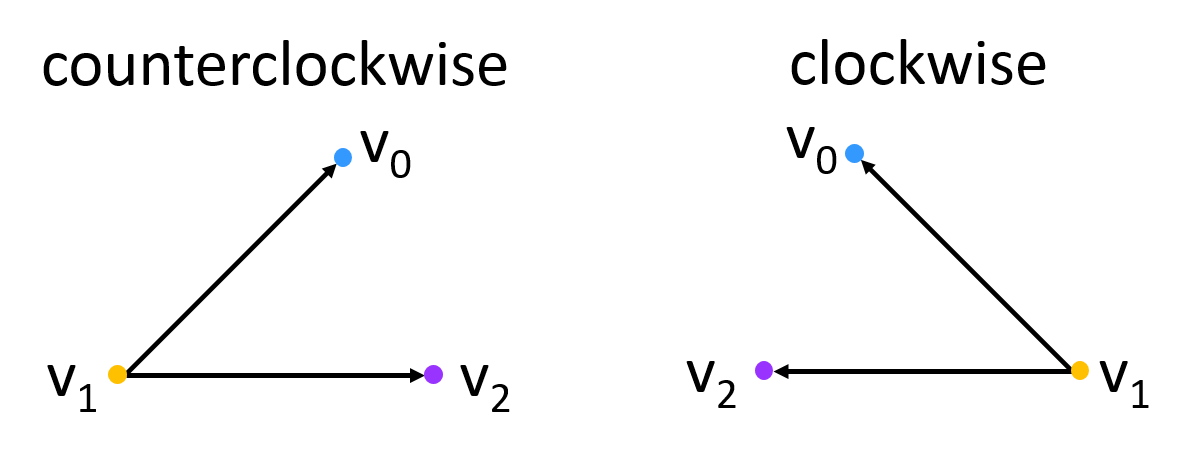
In computer graphics, we use the convention that triangles whose vertices are listed incounterclockwise order face toward the camera. And triangles whose vertices are listedin clockwise order face away from the camera. For an example of a case where a triangle
faces away from the camera, just consider all the triangles on the backside of the sphere in Figure
11. Half of the sphere surface is facing towards us, and half of it is facing away from
us.
If a triangle with vertices
were facing toward the camera, then the cross product of vectors
and
in NDC results in
a vector whose
component is positive in NDC. On the other hand, the same calculation
on a back-facing triangle would result in a vector with a negative
component in NDC. Consider Figure 12:
Figure 12: For a triangle facing towards the camera, the vertices are given in
counterclockwise order, and the cross product of the two shown vectors results in a vector
with a positive
component in NDC. For a triangle facing away from the camera, the vertices are given in
clockwise order, and the cross product has a negative
component in NDC. The sign of the
component can be verified using the right-hand rule.
Recall that NDC has an inverted z-axis. Keeping this in mind, we can use the right-hand rule to verify
that has a
positive
component in NDC for front-facing triangles and a negative
component for back-facing triangles.
We can now incorporate depth buffering and backface culling into our Gouraud shading algorithm.
To do so, we only need to change Algorithm 5 in the Gouraud Shading section. Algorithm 4 from
the same section remains the same.